Prometheus는 최신 인프라스트럭쳐에서 널리 사용되는 인기 있는 오픈소스 시스템 모니터링 및 Alert Toolkit입니다. Prometheus의 주요 기능과 장점은 다음과 같습니다.
-
확장성 (Scalability): Prometheus는 확장 가능하고 효율적으로 설계되었으며 수백만 개의 메트릭과 초당 수십만 개의 샘플을 처리할 수 있습니다. 풀(Pull) 모델을 사용하는데, 이 모델에서 Prometheus 서버는 모니터링되는 시스템에서 노출된 Exporter의 메트릭을 주기적으로 스크랩하고 수집된 메트릭을 내부 시계열 데이터베이스에 저장합니다. 이를 통해 Prometeus는 모니터링되는 시스템을 압도하지 않고 대량의 메트릭 데이터를 수집하고 저장할 수 있습니다.
-
유연성 (Flexibility): Prometheus는 다양한 메트릭 타입 및 레이블을 지원하고 수집된 메트릭을 쿼리, 분석 및 시각화하기 위한 풍부한 쿼리 언어 및 API를 제공합니다. 이를 통해 사용자는 다양한 시스템과 소스를 모니터링하고 시스템의 성능과 동작을 매우 자세하게 이해할 수 있습니다.
-
통합 (Integration): Prometheus는 대시보드용 Grafana, 경고용 Alertmanager 또는 다양한 시스템 및 소스에서 메트릭을 수집하기 위한 다양한 Exporter 및 시스템과 통합할 수 있습니다. 이를 통해 사용자는 특정 요구 사항들을 충족하는 모니터링 인프라를 구축할 수 있습니다.
-
커뮤니티 (Community): Prometheus는 사용자에게 풍부한 리소스와 지원을 제공하는 크고 활동적인 커뮤니티가 있는 오픈 소스 프로젝트입니다. 여기에는 설명서, 자습서, 모범 사례 및 다양한 시스템과 소스를 모니터링하는 데 사용할 수 있는 다양한 Integration 및 Exporter가 포함됩니다.
Prometheus는 최신 인프라에 적합한 기능이 풍부하고 유연한 모니터링 도구입니다. 메트릭 데이터를 수집, 저장 및 쿼리하는 확장 가능하며 효율적인 방법을 제공하고 사용자가 시스템의 성능과 동작을 매우 자세하게 모니터링하고 이해할 수 있도록 합니다.
¶ 메트릭 수집
Prometheus가 메트릭을 수집하는 원리는 간단합니다. 풀(Pull) 모델을 사용합니다. 풀 모델에서는 Prometheus 서버가 서비스에 노출된 Exporter에 주기적으로 HTTP 요청을 보내 다양한 엔드포인트의 메트릭을 스크랩핑합니다. Exporter는 Prometheus 서버에서 쉽게 파싱할 수 있는 텍스트 파일 같은 특정 형식으로 메트릭 데이터를 제공하는 역할을 합니다.
풀(Pull) 모델에 대하여
Prometheus는 다양한 시스템 및 소스에서 메트릭을 수집하기 위해 풀 모델을 사용합니다. 풀 모델에서 Prometheus 서버는 "스크랩"이라고 불리는 HTTP 요청을 모니터링되는 시스템에 노출된 Exporter로 정기적으로 전송합니다. Exporter는 Prometheus 서버에서 쉽게 구문 분석할 수 있는 텍스트 파일과 같은 특정 형식으로 메트릭 데이터를 제공하는 역할을 합니다.
모니터링되는 시스템이 메트릭 데이터를 Prometheus 서버로 직접 보내는 푸시(Push) 모델에 비해 몇 가지 장점이 있습니다.
Prometheus 서버가 메트릭을 수집하는 속도를 제어하고 서버의 워크로드 및 리소스에 따라 속도를 조정할 수 있습니다. 이렇게 하면 대량의 메트릭 데이터로 인해 서버가 과부하되는 것을 방지할 수 있습니다.
모니터링되는 시스템에서 Prometheus 서버를 분리하고 서버가 Exporter를 노출하는 모든 시스템에서 메트릭을 수집할 수 있도록 합니다. 이는 새로운 시스템과 소스를 지원하도록 쉽게 확장할 수 있으므로 모니터링 인프라를 보다 유연하고 확장 가능하게 만듭니다.
Prometheus 서버가 메트릭 데이터를 캐시하고 내부 시계열 데이터베이스에 저장하기 전에 데이터에 대한 변환을 수행할 수 있습니다. 이렇게 하면 서버의 저장 및 처리 요구 사항이 줄어들고 사용자가 메트릭 데이터를 보다 효율적으로 저장하고 쿼리할 수 있습니다.
풀 모델은 Prometheus 모니터링 시스템의 중요한 측면이며 이를 통해 서버는 확장 가능하고 효율적인 방식으로 다양한 시스템 및 소스에서 메트릭 데이터를 수집하고 저장할 수 있습니다.
시계열(Time-series) 데이터베이스에 대하여
시계열 데이터베이스는 시간이 지남에 따라 수집 및 저장되는 데이터인 시계열 데이터를 저장 및 분석하도록 특별히 설계된 데이터베이스입니다. 시계열 데이터는 보통 정기적으로 수집되며 시간의 흐름에 따른 시스템, 애플리케이션 또는 프로세스의 성능과 동작을 추적하는 데 자주 사용됩니다.
시계열 데이터베이스는 대량의 시계열 데이터를 저장하고 쿼리하는 데 최적화되어 있으며 효율적인 데이터 압축, 빠른 쓰기, 복잡한 쿼리 및 집계 지원과 같은 기능을 제공합니다. 시스템 성능, 리소스 사용 또는 비즈니스 메트릭과 같은 메트릭을 추적하는 데 사용할 수 있는 모니터링 및 분석 애플리케이션에서 자주 사용됩니다.
시계열 데이터베이스의 예로는 Prometheus, InfluxDB 및 Graphite가 있습니다. 이러한 데이터베이스는 다양한 기능을 제공하며 다양한 사용 사례 및 워크로드의 특정 요구 사항과 요구 사항을 충족하도록 설계되었습니다.
Prometheus 서버는 수집된 메트릭을 내부 시계열 데이터베이스에 저장하고 데이터 쿼리, 분석 및 시각화를 위한 풍부한 쿼리 언어 및 API를 제공합니다. 또한 수집된 메트릭 및 사용자 정의 규칙을 기반으로 알림을 트리거하거나 자동화된 작업을 수행할 수 있는 경고 엔진이 포함되어 있습니다.
Prometheus 수집 메트릭의 원리에 대한 자세한 설명은 다음과 같습니다.
-
Prometheus 서버는 다양한 시스템 및 소스에서 메트릭을 수집하는 역할을 합니다. 모니터링되는 시스템에 노출된 Exporter에 "스크랩"이라고 하는 HTTP 요청을 주기적으로 전송하여 이를 수행합니다. 이러한 내보내기는 Prometheus 서버에서 쉽게 구문 분석할 수 있는 텍스트 파일과 같은 특정 형식으로 메트릭 데이터를 제공하는 역할을 합니다.
-
Exporter는 독립 실행형 프로세스로 구현하거나 모니터링되는 시스템에 내장할 수 있는 라이브러리로 구현할 수 있습니다. 이들은 일반적으로 메트릭의 다른 인스턴스 또는 차원을 구별하는 데 사용할 수 있는 선택적 레이블과 함께 메트릭 이름 및 값으로 구성된 Prometheus 형식으로 메트릭 데이터를 제공하는 HTTP 엔드포인트을 노출합니다.
-
Prometheus 서버는 대량의 시계열 데이터를 저장하고 쿼리하는 데 최적화된 내부의 시계열 데이터베이스에 수집된 메트릭을 저장합니다. 데이터베이스는 각각 고정된 시간 간격을 나타내는 일련의 블록으로 구성되며 각 블록에는 메트릭 이름 및 레이블의 매트릭스로 저장되는 시계열 데이터 요소 집합이 포함됩니다.
-
Prometheus 서버는 수집된 메트릭을 쿼리, 분석 및 시각화하기 위한 풍부한 쿼리 언어 및 API를 제공합니다. PromQL이라는 쿼리 언어를 사용하면 메트릭 데이터를 다양한 방식으로 필터링, 집계 및 변환하는 복잡한 쿼리를 지정할 수 있습니다. API를 통해 사용자는 원시 데이터 포인트 검색, 데이터를 외부 시스템으로 내보내기 또는 경고 생성 및 관리와 같이 수집된 메트릭에 대해 다양한 작업을 수행할 수 있습니다.
-
Prometheus 서버에는 수집된 지표 및 사용자 정의 규칙을 기반으로 알림을 트리거하거나 자동화된 작업을 수행할 수 있는 경고 엔진도 포함되어 있습니다. 사용자는 수집된 메트릭 값과 해당 임계값을 기반으로 경고가 트리거되어야 하는 시기를 지정하는 규칙을 정의할 수 있습니다. 경고 엔진은 수집된 메트릭에 대해 규칙을 지속적으로 평가하고 규칙이 충족되면 알림을 보내거나 작업을 수행합니다.
전반적으로 Prometheus 수집 메트릭의 원칙은 다양한 시스템과 소스를 모니터링할 수 있는 유연하고 확장 가능한 방법을 제공하고 사용자가 수집된 데이터를 쉽게 쿼리, 분석 및 시각화할 수 있도록 하는 것입니다. 이를 통해 사용자는 시스템의 성능과 동작을 이해하고 문제가 심각해지기 전에 식별하고 해결할 수 있습니다.
¶ 메트릭 수집 샘플
-
먼저 Prometheus 서버를 설치 및 구성하고 모니터링할 시스템과 소스를 결정해야 합니다. 모니터링되는 시스템에 Exporter를 설정하거나 Prometheus와 호환되는 기존 Exporter를 사용할 수 있습니다.
-
다음으로 Prometheus 서버가 메트릭을 위해 스크랩해야 하는 대상(Exporter)을 지정해야 합니다. 이는 일반적으로 Exporter URL, 스크래핑 간격 및 인증 또는 TLS 설정과 같은 기타 옵션을 지정할 수 있는 Prometheus 구성 파일에서 수행됩니다.
-
Prometheus 서버는 구성된 간격으로 지정된 대상을 스크래핑하기 시작하고 내부 시계열 데이터베이스에서 메트릭 데이터를 수집합니다. 수집된 메트릭은 Prometheus 쿼리 언어 및 API를 사용하여 쿼리 및 분석하거나 Grafana와 같은 대시보드 도구를 사용하여 시각화할 수 있습니다.
다음은 메트릭을 스크랩할 두 대상을 지정하는 Prometheus 구성 파일의 예입니다.
global:
scrape_interval: 15s
scrape_configs:
- job_name: my_system
static_configs:
- targets: ['localhost:9090', 'localhost:9191']
이 구성은 Prometheus 서버가 대상 localhost:9090 및 localhost:9191을 15초마다 스크랩핑하고 수집된 메트릭를 시계열 데이터베이스에 저장하도록 설정합니다. 대상은 로컬에서 실행 중인 Exporter이거나 네트워크를 통해 액세스할 수 있는 원격 Exporter일 수 있습니다.
¶ 메트릭 데이터 샘플
메트릭 구문은 HTTP를 통해 메트릭 데이터를 노출되며, 사람이 읽을 수 있는 형식인 Prometheus 텍스트 형식을 기반으로 합니다. 텍스트 형식은 메트릭의 다른 인스턴스 또는 차원을 구별하는 데 사용할 수 있는 선택적 레이블과 함께 메트릭 이름 및 해당 값을 나타내는 텍스트 행으로 구성됩니다.
-
메트릭 이름/타입(Name/Type): 각 메트릭은
HELP및TYPE주석을 사용하여 지정되는 이름과 타입으로 식별됩니다. 'HELP' 주석은 메트릭은 대한 간략한 설명을 제공하고 'TYPE' 주석은 메트릭의 타입을 지정합니다. 타입에는counter,gauge,histogram,summary, 또는untyped을 사용할 수 있습니다. -
레이블(Labels): 각 메트릭에는 다른 인스턴스 또는 차원을 구분하는 데 사용되는 하나 이상의 레이블이 있을 수 있습니다. 레이블은 키-값 쌍으로 지정되며 String 입니다.
-
메트릭 값(Value): 각 메트릭에는 부동 소수점 숫자로 지정된 하나 이상의 값이 있습니다. 값은 특정 시점의 메트릭 값을 나타내는 인스턴트 값이거나 메트릭이 재설정되거나 시작된 이후 메트릭의 총량을 나타내는 누적 값일 수 있습니다.
메트릭 타입(Metric Types)에 대하여
counter: 카운터는 단조롭게 증가하는 값을 나타내는 누적 메트릭입니다. 일반적으로 시간 경과에 따른 이벤트 수 또는 메트릭의 총량을 추적하는 데 사용됩니다. 메트릭을 내보내는 프로세스가 다시 시작되면 카운터가 0으로 재설정됩니다.
gauge: 게이지는 임의로 오르내릴 수 있는 단일 수치를 나타내는 메트릭입니다. 일반적으로 지정된 시점에서 메트릭의 현재 값을 추적하는 데 사용됩니다.
histogram: 히스토그램은 버킷 집합에 대한 메트릭 분포를 추적하는 메트릭입니다. 각 버킷에 속하는 이벤트 수에 대한 누적 카운터 세트와 이벤트 수 및 합계로 구성됩니다. 히스토그램을 사용하여 대기 시간 또는 기타 메트릭 값의 분포를 추적할 수 있습니다.
summary: 요약은 분위수 집합에 대한 메트릭 분포를 추적하는 메트릭입니다. 이벤트 수와 합계에 대한 누적 카운터 세트와 이벤트 분포를 추정하는 데 사용할 수 있는 분위수 세트로 구성됩니다. 요약은 대기 시간 또는 기타 메트릭 값의 분포를 추적하는 데 사용할 수 있습니다.
untyped: 타입이 지정되지 않은 메트릭은 타입이 지정되지 않은 메트릭입니다. 일반적으로 메트릭 타입을 알 수 없거나 메트릭이 자리 표시자로 사용되는 경우에 사용됩니다.
TYPE주석은 선택 사항이지만 메트릭 타입 및 해석 방법에 대한 정보를 제공하기 위해 메트릭 데이터에 포함하는 것이 좋습니다. 메트릭 타입은 Prometheus 서버 및 기타 도구에서 메트릭을 저장, 쿼리 및 시각화하는 방법에 영향을 줄 수 있습니다.
다음은 단일 레이블과 인스턴스 값이 있는 메트릭의 예입니다.
# HELP my_metric A metric that represents the number of requests
# TYPE my_metric counter
my_metric{method="GET", status_code="200"} 10
이 예에서 메트릭의 이름은 'my_metric'이고 타입은 'counter'입니다. 값이 "GET"인 method와 값이 "200"인 status_code의 두 레이블이 있습니다. 메트릭 값은 10입니다.
다음은 여러 레이블과 누적 값이 있는 메트릭의 예입니다.
# HELP http_request_duration_seconds The HTTP request latencies in seconds
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.1"} 24054
http_request_duration_seconds_bucket{le="0.2"} 33444
http_request_duration_seconds_bucket{le="0.5"} 100392
http_request_duration_seconds_bucket{le="1"} 129389
http_request_duration_seconds_bucket{le="+Inf"} 133988
http_request_duration_seconds_sum 53423
http_request_duration_seconds_count 133988
이 예에서 메트릭의 이름은 'http_request_duration_seconds'이고 타입은 'histogram'입니다. 각 버킷에 대해 다른 값(예: "0.1", "0.2" 등)을 갖는 단일 레이블 le이 있습니다. 메트릭 값은 각 버킷에 속하는 요청 수의 누적 개수입니다. 메트릭에는 평균 대기 시간을 계산하는 데 사용할 수 있는 요청 대기 시간의 합계와 개수도 포함됩니다.
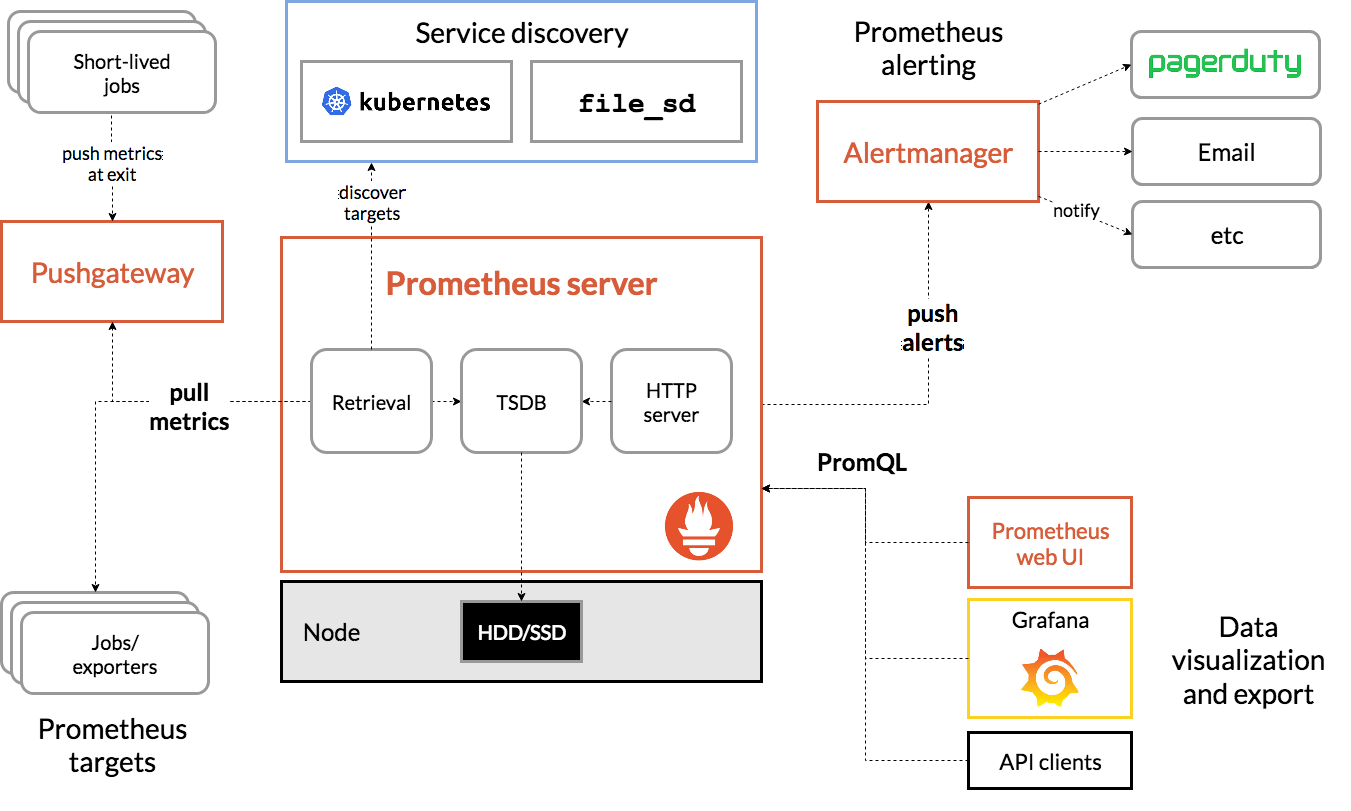
¶ 부록: 인프라스트럭쳐
Prometheus 기반 인프라의 구조는 일반적으로 다음 구성 요소로 구성됩니다.
Prometheus 서버: 다양한 시스템 및 소스에서 메트릭을 수집하고 내부 시계열 데이터베이스에 수집된 메트릭을 저장하고 쿼리, 분석, 데이터를 시각화합니다.
Exporter: Prometheus 형식으로 메트릭 데이터를 노출하고 Prometheus 서버에서 스크랩할 수 있는 독립 실행형 프로세스 또는 라이브러리입니다. Exporter는 데이터베이스, 네트워크, 애플리케이션 또는 하드웨어 장치와 같은 다양한 시스템 및 소스에 대해 구현될 수 있습니다.
Alertmanager: Prometheus 서버와 함께 사용하여 알림을 트리거하거나 수집된 메트릭 및 사용자 정의 규칙에 따라 자동화된 작업을 수행할 수 있는 선택적 구성 요소입니다. Alertmanager는 Prometheus 서버에서 경고를 수신하여 그룹화하고 알림을 보내거나 구성된 정책에 따라 작업을 수행합니다.
Grafana: 수집된 메트릭을 시각화하고 대화형 대시보드를 만드는 데 사용할 수 있는 인기 있는 대시보드 도구입니다. Grafana는 Prometheus 서버 또는 Alertmanager와 통합할 수 있으며 메트릭 데이터를 다양한 차트 및 그래프로 표시할 수 있습니다.
모니터링되는 시스템 및 소스: Prometheus 서버에서 모니터링하고 내보내기를 통해 메트릭 데이터를 노출하는 시스템 및 소스입니다. 서버, 애플리케이션, 데이터베이스, 네트워크 또는 기타 타입의 시스템 및 소스가 될 수 있습니다.
Prometheus 기반 인프라의 구조는 다양한 시스템 및 소스에서 메트릭을 수집하고 데이터 쿼리, 분석 및 시각화를 위한 풍부한 쿼리 언어 및 API를 제공하는 Prometheus 서버를 중심으로 합니다. 인프라에는 모니터링 시스템의 기능과 기능을 확장하는 데 사용할 수 있는 내보내기, Alertmanager 및 Grafana와 같은 추가 구성 요소도 포함될 수 있습니다.